Устный
В рамках проекта РГНФ была записана живая речь калмыков, преимущественно старшего поколения, поскольку представители этой возрастной группы владеют языком свободно. Такое расширение задач проекта позволяет сфокусировать свои исследования не только на письменных источниках, в которых в основном не проявляются диалектные черты автора текста в силу разных причин.
Живая речь носителей языка может сильно отличаться от письменной, и здесь речь идет не сколько о характерных особенностях устной речи (повторы, паузы хезитации, обрывы и др.), а столько о том, что в их языке могут иметь место различные элементы диалектной системы, которые описаны или не описаны в калмыцкой диалектологии. Если на уровне письменных текстов уже разработана система помет того или иного диалекта, которая, по сути, ничего не дает исследователю-диалектологу и является скорее дескриптивной, то на материале текстов, записанных от носителей калмыцкого языка мы получим новый материал, в котором можно обнаружить нечто новое, являющееся проявлением функционирования реликтовых форм в языке.
В результате анализа опыта составления диалектных и устных корпусов было решено, что наилучшим способом презентации материала текстов является фонетическая транскрипция звучащей речи, наряду с орфографической записью. Именно она позволит сохранить все особенности диалекта, хотя это, конечно, не отменяет необходимости записывать нетекстовый материал на основе вопросников для сбора диалектологического материала.
1. Условия записи устной речи. Запись в основном проводилась в помещениях, где нет сильного зашумления помехами (например, голосами других людей, шума машин, работающих электроприборов и т. д.). Использовался диктофон с выносным микрофоном (лучше всего с встроенной системой подавления шумов с постоянной частотой). Признаком хорошей записи считалась расшифровка с первого раза, без многократного прослушивания.
2. Выбор информантов определялся задачами лингвистического исследования. В идеале информанты в целом должны отражать генеральную совокупность, т. е. это люди разного возраста и пола, социального статуса, профессий, диалектной принадлежности. Однако в сложившейся языковой ситуации представители молодого и среднего поколения не владеют языком вообще или ограниченно.
Тем не менее существовало четкое требование в процессе отбора информантов: все должны были владеть достаточно свободно калмыцким языком и иметь высокую языковую компетенцию, и желательно, чтобы первичным языком был именно калмыцкий.
3. Составление анкет. Каждый информант должен был заполнить анкеты, необходимые для последующего лингвистического анализа записанных текстов.
Пример анкеты
АНКЕТА ИНФОРМАНТА №___
1. Ваша фамилия, имя, отчество (по желанию):
2. Пол: мужской, женский (нужное подчеркнуть).
3. Возраст (год роҗдения и год по калмыцкому календарю)
4. Национальность
5. Субэтническая группа: дербеты, торгуты, бузавы, хошуды (нужное подчеркнуть)
6. Этнические маркеры и род внутри группы арван, ясн, төрл, өлгц, туг, уран
7. Знаете ли Вы свою родословную?
8. Где Вы родились?
9. Где провели детство?
10. Где провели юность?
11. Место проживания в настоящее время (укажите район, село, город)
12. Образование: среднее, среднее специальное, высшее (нужное подчеркнуть)
13. Где и кем работаете (работали)?
14. Район проживания до депортации
15. Район депортации (если были депортированы)
16. Район возращения после депортации
17. Участник ВОВ: да, нет (нужное подчеркнуть, укажите, в каких частях служили)
18. Расскажите о супруге (место рождения, год рождения, год рождения по калмыцкому календарю, род, арван, ясн, төрл, өлгц, туг, уран)
19. Первичный язык (т. е. тот язык, который первым усвоили)
20. Какими еще языками владеете?
21. Время изучения других языков
22. В какой мере вы владеете калмыцким языком? (нужное подчеркнуть)
· Свободно разговариваю, читаю и пишу, думаю на родном языке;
· Неплохо разговариваю, часто думаю на родном языке, относительно хорошо читаю и пишу;
· Разговариваю и думаю на родном языке, но не умею читать и писать;
· Понимаю, но говорю с трудом;
· Говорю с трудом и плохо понимаю.
23. На каком языке вы говорите в семье, на работе, во время учебы, в общении с друзьями? (нужное подчеркните)
· только на родном языке (в семье, на работе, во время учебы, в общении с друзьями);
· в основном на родном языке (в семье, на работе, во время учебы, в общении с друзьями);
· в одинаковой степени на русском и калмыцком языках (в семье, на работе, во время учебы, в общении с друзьями);
· в основном на русском языке (в семье, на работе, во время учебы, в общении с друзьями);
· только на русском языке (в семье, на работе, во время учебы, в общении с друзьями).
24. Знаете ли Вы фольклорные произведения на калмыцком языке? Если да, то укажите, пожалуйста, жанры: эпос, мифы, предания, сказки, песни, пословицы, поговорки, загадки и др.
25. Знаете ли Вы калмыцкие обычаи и традиции?
26. Контактные данные
4. Отбор тем для беседы. Поскольку в Калмыкии калмыцкий язык как средство коммуникации и познания утрачивается, то создать сбалансированную и более или менее полную коллекцию речевых сценариев априори уже невозможно, но, тем не менее, мы выработали примерный круг тем для сбора диалектного и устного материала. В качестве исходной посылки выступает идея, которая заключается в том, что одна и та же тема для разговора будет содержать одинаковую лексику, которая будет появляться естественным образом у разных информантов, с одной стороны. С другой – в связном тексте «работает» морфология и синтаксис языка, не говоря уже о фонетике. Тексты, записанные от информанта, в большей степени отражают речь в естественных условиях.
5. Ход записи устной речи. Сбор материала проводился по программе, определенной заранее. Выявление диалектных особенностей производилось в ходе направленной беседы. При подготовке к беседе обдумывался план разговора, формулировка вопросов. Перед записью информант получал свой индивидуальный номер у ответственного за регистрацию, который фиксирует номер, дату записи, ответственного за запись в таблице.
До записи лингвист инструктировал информанта, который должен заполнить анкеты с помощью исследователя. Важно в процессе заполнения анкеты расположить информанта к беседе, заполнять анкету может и исследователь, и сам информант. Задавать вопросы в процессе заполнения анкеты нужно только на калмыцком языке, тем самым лингвист помогает быстрее переключится информанту с одного кода на другой.
Ответственный создавал папку под названием Informant-00 (вместо 00 пишется номер информанта, который был ему присвоен при регистрации), обязательно используя латинские буквы. Внутри данной папки создавалось несколько папок. Исходные звуковые файлы копировались в созданную папку Iskhodnye с теми же названиями, которые были автоматически даны диктофоном или записывающей программой на компьютере. Если даже файлы "пустые", т. е. на них не записана речь информанта и его коммуникантов, то он ни в коем случае не удалялся. Обработанный материал помещался в папку Obrabotannye, а расшифровка звуковых файлов сохранялась в другой папке (Decoding).
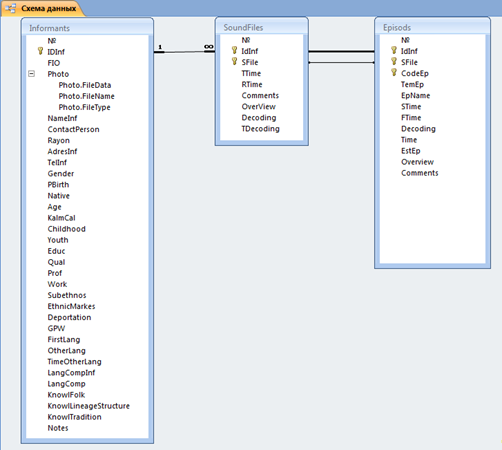
Звуковой корпус по калмыцкому языку состоит из трех модулей: базы данных "KalmykSpeech", звуковых файлов и расшифровок в формате .eaf. Общая метаинформация, собранная в процессе заполнения анкеты, фиксировалась в специально созданных таблицах в программе Access MS Office. Таблицы Informants, SoundFiles, Epizods связаны друг с другом при помощи общих полей (ниже приведена схема данных).
Рис. 1. Схема данных базы "KalmykSpeech"
Далее файл передавался лингвисту, который предварительно проводил процедуру автоматической шумоочистки (программе после предоставления образца шума статистического характера удаляет данные частоты на протяжении всего звукового файла). Расшифровка (и скоростная, и детальная) проводится в специально разработанной для полевой работы программе Elan 4.0. Далее исследователь производит аннотирование звукового файла, которое на данном этапе состоит из следующих уровней:
1) уровень макроэпизодов;
2) уровень информанта и коммуниканта (коммуникантов);
3) уровень предложений в орфографической расшифровке;
4) уровень предложений в фонетической расшифровке.
Первоначально исследователь проводил скоростную расшифровку, указывая речевые эпизоды, под которыми понимаются макроэлементы, являющиеся законченными смысловыми отрезками речи. Чаще всего эпизоды соответствуют речевому сценарию. Например, разговор о погоде, рассказ о своем детстве и т. д. Индексом А0 обозначается отрезок звукового файла, который оценивается как «мусор». Например, включение диктофона, проверка и т. п.
Аннотирование на уровне предложений в орфографической записи происходит по следующим правилам:
1) знаком (/) обозначается конец синтагмы;
2) знаком (//) – конец высказывания повествовательного характера;
3) знаками (?) и (!) – конец высказывания вопросительного и восклицательного характеров;
4) знаком (…) – обрыв слова без пробела перед последующим словом;
5) знаком ( …) – обрыв высказывания с пробелом перед последующим словом;
6) знаком (//-//) – длительная пауза хезитации;
7) (...) – незаполненная пауза хезитации (например, запинка, которая перцептивно ощущается);
8) (э-э, а-а, м-м и т.д.) – заполненная пауза хезитации;
9) @ … @ – речь коммуникантов или на фоне разговора информанта и коммуниканта;
10) # ... # – переключение языковых кодов (например, с калмыцкого на русский и наоборот);
11) *C, *K, *П и др. – паралингвистические элементы речи (например, смех);
12) би-ичә – протяжка того или иного звука в слове.
Аннотирование на уровне предложений в фонетической записи начинается с копирования уровня предложений в орфографической записи. Нами были рассмотрены несколько систем фонетической транскрипции, выработанных лингвистами для различных задач: Международный фонетический алфавит и Уральская фонетическая система. Было решено остановиться на системе Международного фонетического алфавита в несколько упрощенном и слегка модифицированном виде. Это позволит, с одной стороны, расширить круг исследователей, которые интересуются фонетикой калмыцкого языка, с другой стороны, унифицировать подачу произношения в нормативных словарях, что наиболее актуально для языковой ситуации в Калмыкии. В калмыцком письме не обозначаются так называемые «неясные» гласные, что уже привело к негативным последствиям – изменениям в орфоэпии, исчезновению языку, поскольку дети не могут прочитать скопления согласных, не зная, где произнести сверхкраткие гласные. Многие словари используют для передачи произношения слов систему Международного фонетического алфавита, например Oxford Advanced Learner's Dictionary и Cambridge Advanced Learner's Dictionary.
Были выработаны правила применительно к калмыцкому языку и отображают только те качества речи, которые являются дифференцированными (смыслоразличительными) в устной речи. Согласно МФА, речь транскрибируется на латинице с использованием нестандартных символов, поэтому в этих целях был написан специализированный макрос по замене орфографической записи калмыцкой речи кириллическими символами на латинские (см. таблицу символов). Это ускорит расшифровку на фонетическом уровне, хотя это, конечно, незначительно облегчит работу. Было принято решение использовать следующие символы для обозначения звуков калмыцкого языка:
· гласные звуки полного образования: a, ä, o, ö, u, ü, i, e;
· долгие гласные звуки: aː, äː, oː, öː, uː, üː, iː, eː;
· сверхкраткий гласный звук: ә;
· согласные звуки: m, p, b, f, v, n, ŋ, t, d, s, z, r, l, j, k, g, χ, ʁ, ʦ, ʨ, ʥ, ʣ, ʧ, ʃ;
· ʲ – знак палатализации;
· ‿ – знак объединения орфографических слов в одно фонетическое.
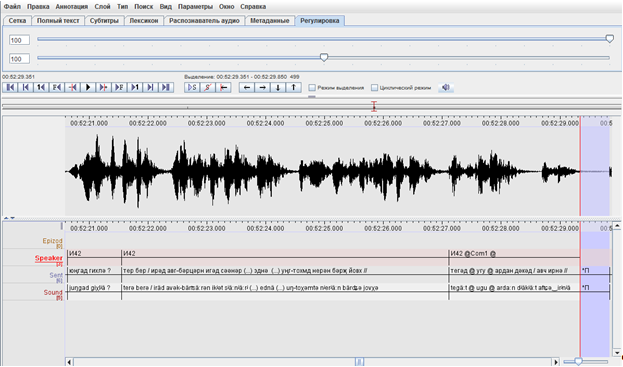
Ниже приведен образец расшифровки в программе ELAN.
Рис. 2. Образец расшифровки устной речи в программе ELAN