Метаразметка
Наличие метатекстовой информации позволит исследователю очертить рамки поисков языковых фактов и явлений в многомиллионном массиве текстов. Признаки, которые необходимо описать в данном модуле, должны быть релевантными, то есть те, которые могут влиять на характеристики текста. Например, с одной стороны, время создания текста обусловливает особенности языка автора, с другой – время, описываемое в тексте, отражает особенности эпохи (автор, используя прием стилизации, вводит названия предметов и реалий в лексическую систему произведения, которые отсутствуют уже во время создания текста).
В ходе обработки текстов было принято решение хранить метатекстовую информацию текстов корпуса калмыцкого языка в базе данных, сконструированную в MS Access 2007. База данных состоит из трех взаимосвязанных таблиц, которые позволяют оперативнее вносить метатекстовую информацию: «Authors», «Books» и «Texts».
Таблица «Authors» включает характеристику авторов. Здесь фиксируется ФИО автора на русском и калмыцком языках, а также его псевдоним, известный широкому кругу читателей. В таблицу входят записи «автор не установлен» и «коллективный автор». Первое поле указывается в случае, когда автор не известен, и чаще всего это группа авторов, которые создают один продукт, например конституцию. Если же авторство текста принадлежит всему народу, то здесь используется в описании вторая вышеуказанная запись. Авторов, пишущих на калмыцком языке, не так много, как, например, на русском языке. Все наиболее известные калмыцкие поэты и писатели зафиксированы в таблице, также зафиксированы и переводные авторы, например А.С. Пушкин, И.С. Тургенев, А.П. Чехов и другие, а также ряд авторов, создавших свои произведения на старокалмыцком языке. В данной таблице дается также более детальная характеристика автора:
· годы жизни (годы рождения и смерти, если это возможно);
· пол (муж. и жен.);
· место рождения;
· первый язык (указывается язык, который был первичным в коммуникации и познании);
· диалект (три пометы: “torgut”, “buzav”, “derbet”);
· знание других языков;
· уровень образования;
· род занятий.
В некоторых случаях невозможно дать исчерпывающую характеристику того или иного автора в силу того, что о нем мало известно или до нас дошли отрывочные сведения о его биографии. Однако по возможности нужно давать полную информацию, поскольку эти атрибуты являются релевантными в изучении влияния социологических факторов на порождение речи. Конечно, все факторы невозможно учесть в процессе исследования, так как их очень много. Это могут быть и ситуативные причины, о которых в большинстве случаев мы ничего не знаем. Но, тем не менее, наиболее адекватные мы постарались указать.
Вторая таблица «Books» описывает книги и в основном служебного характера. Каждая книга имеет свой уникальный номер (тип поля: счетчик), здесь же помечаются редакторы, как правило, ими выступали сами поэты и писатели. Отдельное поле Переводчик (Translator) необходимо для параллельного подкорпуса. Отдельное поле Выходныеданные фиксирует библиографическое описание, при этом было решено не разделять каждый его элемент в отдельное поле, а объединить все библиографическое описание в одно поле. Далее идут служебные поля:
· источник получения текста (издательство, сканирование, электронная копия, ручной набор, Интернет);
· исполнители.
Такая таблица очень удобна тем, что в калмыцкой книжной литературе ХХ века достаточно много переизданий, которые полностью повторяют предыдущие книги, являются результатом контаминации нескольких сборников или только часть (значительная или незначительная по своему объему) является оригинальной. Когда тексты уже зафиксированы по одному сборнику, то внести повторяющееся название можно только после сравнения двух произведений. Столбец, где указывается название текста, является индексируемым полем, при этом повторения недопустимы: система предупреждает, что сохранить данную запись невозможно, поскольку данная запись уже содержится в базе. Однако у авторов существуют произведения с одинаковыми названиями, поэтому после предупреждения, которое выдает программа, необходимо присвоить названию дополнительный индекс, если это все-таки разные произведения. В результате внесения записей в базу данных можно понять, какие книги нам нужно сканировать, а какие не нужно, поскольку они являются переизданиями материала предыдущих книг. Из них выбираются те, которые обладают высоким качеством, необходимым для ускорения процесса распознавания.
Каждому тексту присвоен свой уникальный номер, это ключевое индексируемое поле, создающееся автоматически (тип поля: счетчик). Этот Id позволит связать размеченный с морфологической точки зрения текст и информацию о нем.
В поле «Название текста» фиксируется заглавие текста, вплоть до стихотворений, которые принадлежат жанру «ахр шүлгүд», сотоящие, как правило, из двух-четырех строк. Если название отсутствует, то фиксируется первая строка текста. В полях «Автор» и «Переводчик» из выпадающего списка выбирается автор текста и переводчик, если текст принадлежит переводной литературе.
В поле <lang> указывается язык, на котором впервые создан текст. В большинстве случаев это “xal”, однако в некоторых случаях, в частности для параллельного подкорпуса, отмечается оригинальный язык, на котором создано то или иное произведение. В процессе обработки книжных фондов на калмыцком языке выяснилось, что у нас имеется достаточно большое количество переводных текстов, преимущественно классической литературы с русского языка.
Следующие поля включают уже описание атрибутов самого текста:
· форма речи: письменная или устная;
· графическая система;
· тип речи: поэзия или проза;
· стиль текста: художественный, официально-деловой, научный, разговорный и т.д.;
· жанр текста, включает большое количество элементов;
· выходные данные;
· страницы;
· исполнитель;
· дата регистрации;
· комментарий.
Образцы таблиц представлены ниже (см. рис. 1 и 2). База данных является способом репрезентации метаинформации. Надо сказать, что в процессе заполнения таблиц выявилось, что подавляющее большинство текстов на калмыцком языке – это тексты поэтические. Прозаических текстов достаточно мало, а, как известно, именно они составляют каркас корпуса. Изучать свойства языка на поэтических текстах весьма сложно, поскольку текст стихотворения подчиняется другим правилам. Слово здесь может быть употреблено в метафорическом или метонимическом значении. Создание поэтического языка специфично для каждого автора, и выделить универсальное и специфическое в языке сложно.
База данных перепроверяется исполнителями, устраняются ошибки. Перед публикацией на сайте материалов база данных объединяется с размеченным текстом. Надо сказать, что база данных может быть использована автономно в различных научных целях. Например, созданная база данных может послужить материалом для корпуса названий текстов. Объем базы уже репрезентативен для проведения исследований по заголовкам текстов, написанных на калмыцком языке, при этом она постоянно пополняется новыми записями. Базу данных можно использовать и для поиска материала, где реализована одна и та же тема. Она поможет проследить изменения как хронологически, так и по авторам.
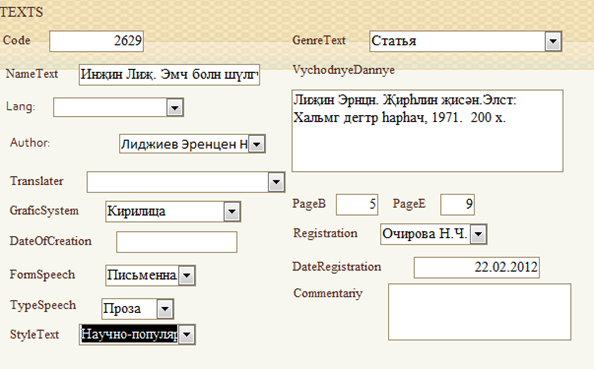
Рис. 1. Образец формы таблицы «Text»
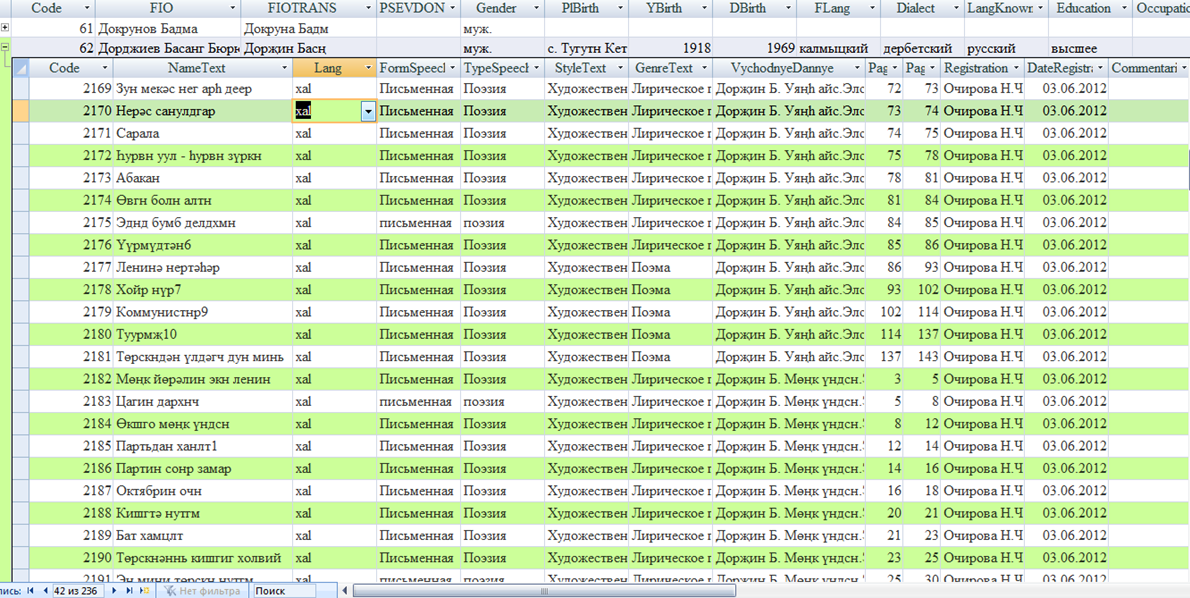
Рис. 2. Образец таблиц «Authors» и «Text»